Heterogene wissenschaftliche Dateistrukturen FAIR gestalten: Eine flexible, robuste Open-Source-Lösung mit dem CaosDB Crawler
Alexander Schlemmer1,2, Henrik tom Wörden2,
Ulrich Parlitz1, Stefan Luther1
Max-Planck-Institut für Dynamik und Selbstorganisation (1), IndiScale GmbH (2)
Was ist CaosDB?
- Semantisches Forschungsdatenmanagementsystem (RDMS)
Fitschen et.al., Data 2019, 10.3390/data4020083 - Entwickelt seit 2010 am MPI für Dynamik und Selbstorganisation (Göttingen)
- Open Source-Projekt seit 2018: gitlab.com/caosdb
- Kommerzieller Support verfügbar durch IndiScale GmbH (seit 2019)
- Aktuell 15 (mir bekannte) Instanzen in sehr verschiedenen Forschungsbereichen
Beispiele für Einsatzbereiche
- MPIDS: Biomedizinische Physik
- MPDL-gefördertes Projekt am MPIDS: CaosDB für Cloud-Kite http://www.bmp.ds.mpg.de/software/mpdlproject/
- Heart&Brain-Database, UMG Göttingen
- Wissensbasis Pandemie-App-Entwicklung https://num.umg.eu/
- Gletscherforschung, Alfred-Wegener-Institut Bremerhaven
- Juristische Datenbank für Richtlinien und Handbücher
- Weitere physikalische Anwendungen über NFDI4Phys
{kind=link}
CaosDB


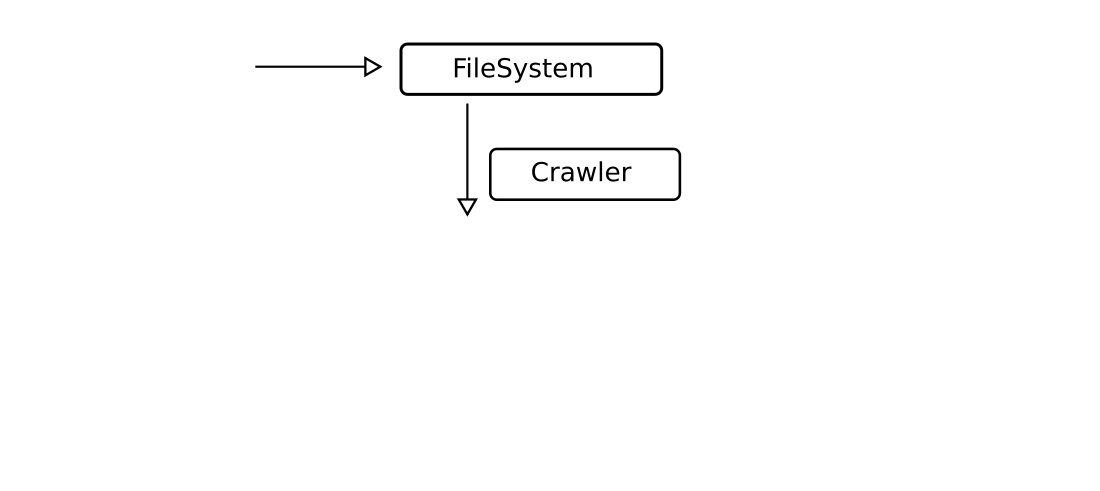

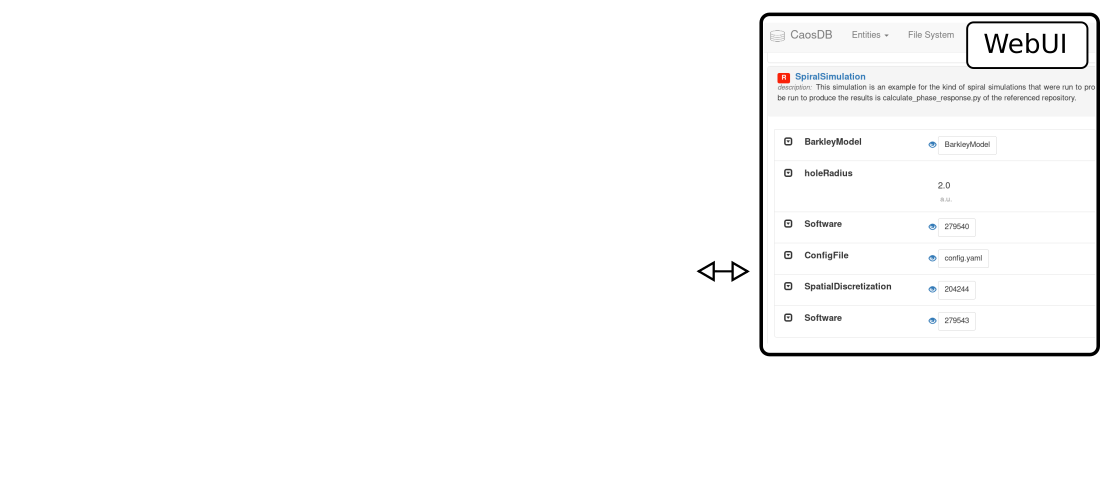

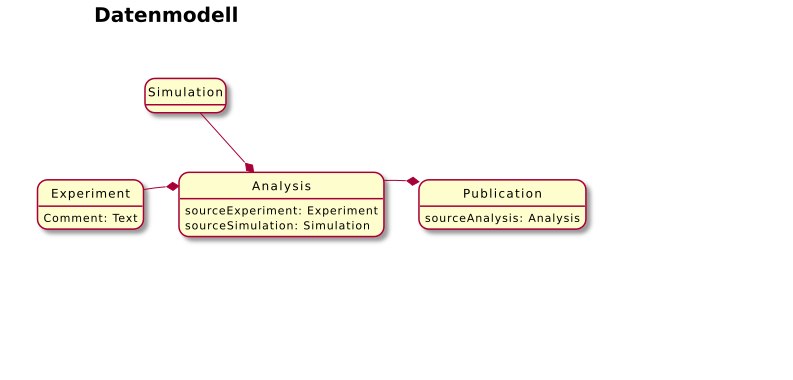
Flexibles Semantisches Datenmodell



Entstehung des Crawlers
- Gruppen-Fileserver für experimentelle Daten
- Dateistruktur sollte erhalten bleiben
- Parallele Nutzung von CaosDB und der Dateistruktur
- Jederzeit Möglichkeit zum alten System zurückzukehren
- Zunächst Python-Skript mit hartgecodeten Regeln
- Später Entwicklung des Crawlers
- modularer Aufbau
- Synchronsierungsfunktion
- Nutzerfeedback
- deklarative Programmierung
Designkonzepte des Crawlers
- Modulares Framework, Python
- Nutzung etablierter Dateistrukturen
- Datenerfassungssoftware, Datenanalysesoftware usw. anbinden
- Verwendung von existierenden Packages für Dateiformate
- Automatisiertes Einfügen und Aktualisieren von Daten
- Individualisierte Datenintegration über Crawler-Plugins (CFoods)
- Referenzierung von Dateien in CaosDB als File-Records
- Integritätsprüfung mit Hashsums
Crawler

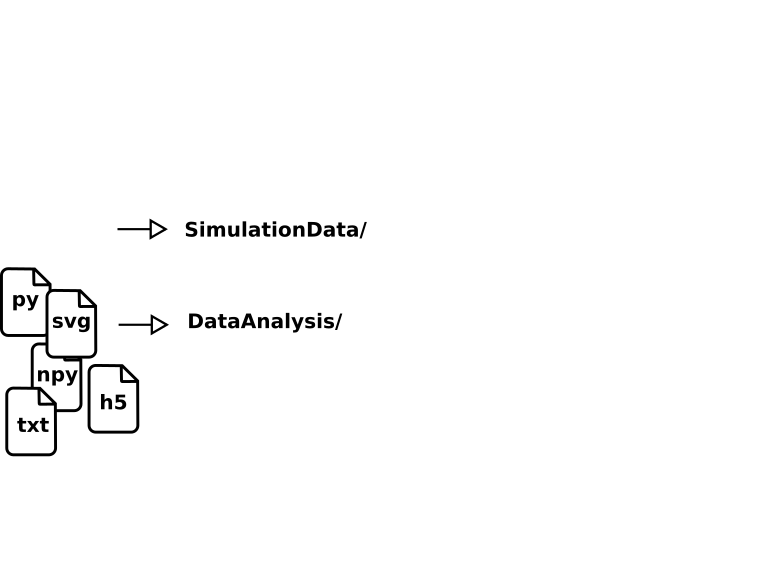

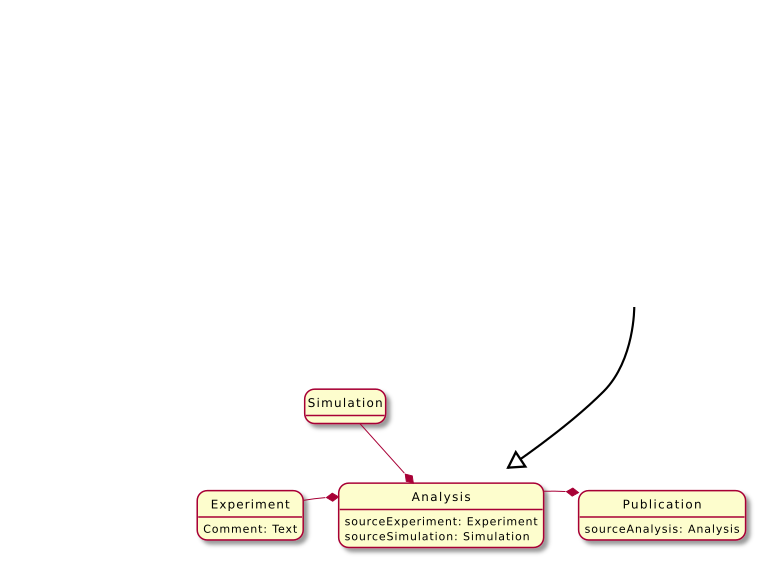
Beispiel: Simulation CFood
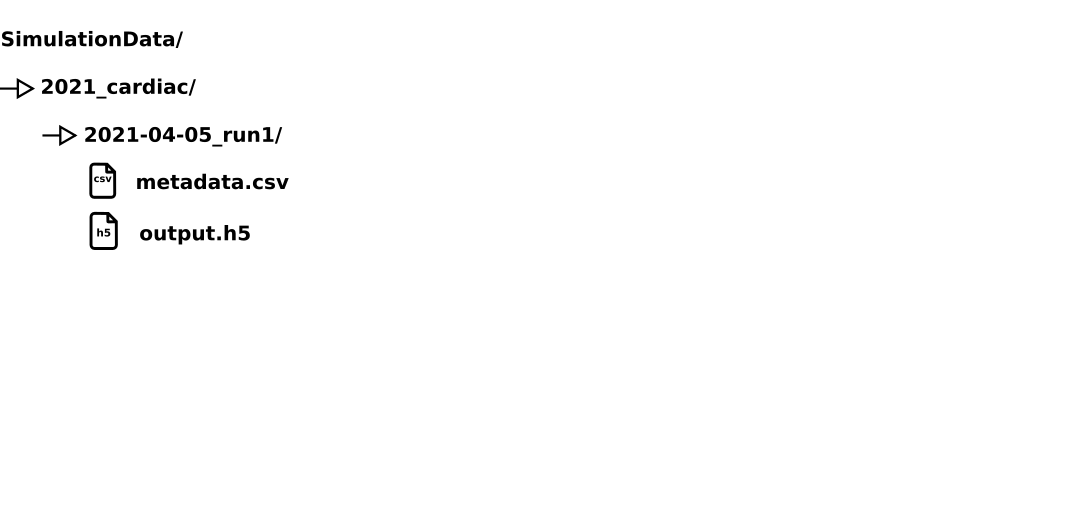




Inkrementelles Entwicklungskonzept


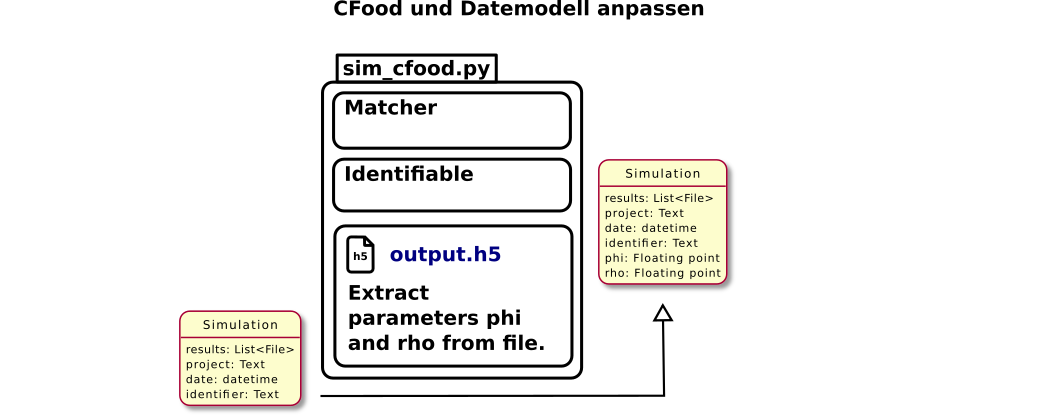

Zusammenfassung
- Crawler synchronisiert Dateisystem mit semantischen Daten in CaosDB
- Beliebige Informationen aus Dateien nutzbar
- Individualisierbar über CFoods
- Parallele Nutzung von CaosDB und der Dateistruktur möglich
- Unterstützt Standardisierung und Dokumentation der Dateistrukturen
Ausblick und Projektinformationen
Work in Progress:
- Einfache alternative Spezifikation von CFoods über Textdateien
- Community-Repositorium für CFoods
- Anbindung an Software/ELNs/Repositorien (z.B. menoci, Labfolder, PANGAEA)
Weitere Informationen:
- www.bmp.ds.mpg.de/software/caosdb und caosdb.org
- Fitschen et.al., Data 2019, 10.3390/data4020083
- Spreckelsen et.al., Data 2020, 10.3390/data5020043
{kind=link}